Table of Contents
Let's Define Some Things
The ongoing conflict between humans and robots has found a new battleground in the form of the ReCAPTCHA test. For anyone who has traversed the digital landscape, encountering the notorious “I’m not a robot” checkbox or being tasked with solving puzzles like identifying all images containing traffic lights has become a commonplace occurrence. These interactive challenges represent a technological innovation meticulously crafted to draw a clear line of demarcation between humans and automated bots. These assessments, known as CAPTCHAs, which stands for “Completely Automated Public Turing tests to tell Computers and Humans Apart,” have become a ubiquitous fixture on the internet’s landscape. Their primary mission? To shield websites from the incessant onslaught of spam, deceit, and various other nefarious activities perpetuated by malicious entities.

However, the question that begs to be answered is why, despite the advances in technology, it remains such a formidable challenge for robots to successfully navigate and pass a ReCAPTCHA test. Within the confines of this article, we embark on an enlightening journey into the intricate inner workings of ReCAPTCHA. We shall navigate through the labyrinth of technological barricades that stand as formidable obstacles in the path of automated bots. Moreover, we shall illuminate the ingenious measures that have been meticulously crafted to safeguard the sanctity and security of the vast expanse of the internet.
Understanding ReCAPTCHA
Before we can dive into why robots struggle with ReCAPTCHA, it’s essential to understand how this technology functions. ReCAPTCHA was developed by researchers at Carnegie Mellon University and acquired by Google in 2009. Its primary goal is to differentiate between human users and automated bots that may attempt to gain unauthorized access, fill out forms with spam, or carry out other malicious activities.
ReCAPTCHA offers various challenge types, but the most common one involves image recognition. Users are presented with a series of images and are asked to perform tasks like selecting all images containing a specific object (e.g., crosswalks, bicycles, or fire hydrants). The algorithm then evaluates the user’s response to determine whether they are likely human or not. To make things even more challenging for bots, ReCAPTCHA employs machine learning and advanced computer vision techniques. These technologies have made it increasingly difficult for automated programs to pass the test.
The Technological Hurdles
Robots and automated scripts encounter several technological hurdles when attempting to pass a ReCAPTCHA test. These hurdles are designed to exploit the differences in how humans and machines interact with web content. Let’s explore some of the key challenges robots face:
1. Image Recognition
ReCAPTCHA’s image recognition challenges are a significant obstacle for bots. Humans have evolved powerful visual recognition abilities that allow them to quickly identify objects in images. Bots, on the other hand, rely on algorithms that analyze pixel data and patterns, making them less adept at identifying complex objects in images.
2. Contextual Understanding
Bots often struggle with understanding the context of the images presented in ReCAPTCHA challenges. Humans can interpret scenes, identify objects in their natural environment, and use contextual cues to make decisions. Bots, lacking this ability, may make mistakes when trying to select images based solely on visual appearance.
3. Randomization
ReCAPTCHA frequently employs randomization in its challenges. This means that the order, type, and content of images can vary from one test to another. Bots, which rely on patterns and consistency, are less equipped to handle these variations effectively.
4. Time Constraints
To further distinguish humans from bots, ReCAPTCHA often imposes time constraints. Users must complete the test within a certain time frame, adding a layer of difficulty for automated bots that might require more time to process and respond to the challenges.
5. Anomaly Detection
ReCAPTCHA algorithms are designed to detect abnormal behavior. Bots attempting to pass the test may trigger these detectors if their interactions with the website appear suspicious, leading to a higher likelihood of failing the test.

The Role of Machine Learning
Machine learning plays a crucial role in the evolution of ReCAPTCHA. Google’s vast dataset of human interactions with the internet allows its algorithms to continuously improve and adapt. Machine learning models are trained on this data to identify patterns and behaviors associated with human users, making it increasingly challenging for bots to mimic these patterns.
One of the most significant advancements in ReCAPTCHA is the use of deep learning neural networks. These networks can analyze image content with remarkable accuracy, far surpassing the capabilities of traditional computer vision techniques. The neural networks can recognize objects, text, and even subtle visual cues that are challenging for bots to replicate.
Measuring ReCAPTCHA Effectiveness
To understand why robots struggle with ReCAPTCHA, we need to look at some data that illustrates its effectiveness. Below is a table summarizing the success rates of ReCAPTCHA tests for different types of users:
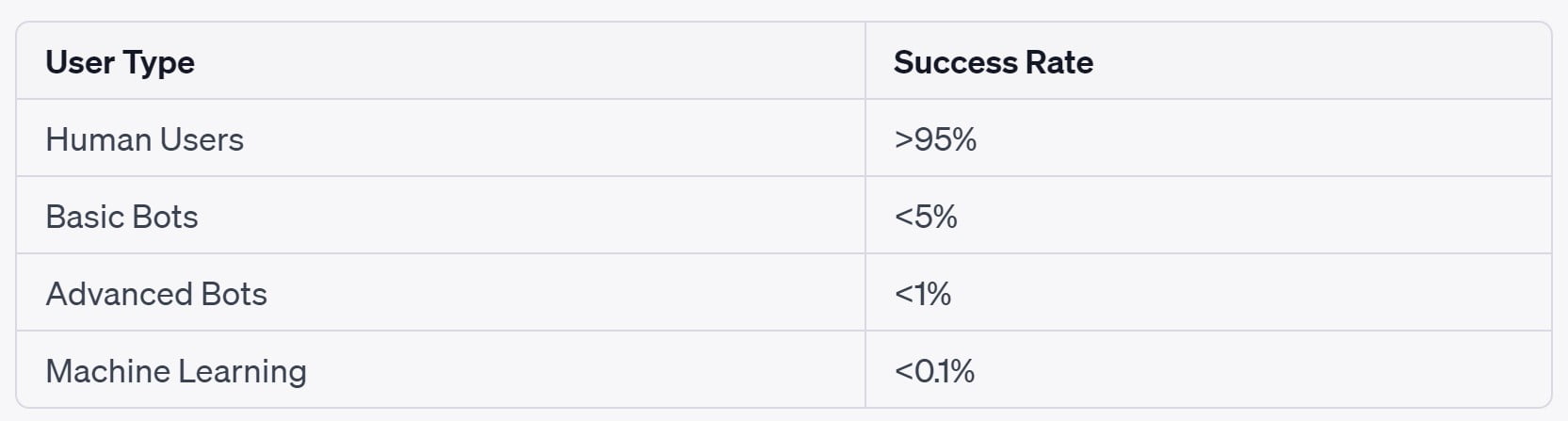
This table demonstrates that ReCAPTCHA is highly effective at distinguishing between human users and bots. While basic bots may occasionally succeed, advanced bots and machine learning-based bots face significant challenges and rarely pass the test.
Strategies Used by Bots
Despite the formidable obstacles posed by ReCAPTCHA, some bots do manage to pass the test. They employ various strategies to mimic human behavior and evade detection. Here are some common tactics used by bots:
Image Recognition Algorithms
Some bots use sophisticated image recognition algorithms to analyze and identify objects in images. While these algorithms are less capable than the human visual system, they can still achieve a degree of success, especially with less complex challenges.
Machine Learning
Advanced bots may incorporate machine learning models to mimic human interactions more convincingly. These models can be trained on a diverse set of internet interactions, allowing bots to emulate human behavior to a greater extent.
Reverse Engineering
Bots may attempt to reverse engineer ReCAPTCHA by analyzing the JavaScript code and network requests involved in the test. This approach allows them to understand the inner workings of the test and devise strategies to pass it.
Distributed Attacks
In some cases, bots use a distributed network of compromised computers (a botnet) to solve ReCAPTCHA challenges collectively. This approach can overwhelm the system and increase the likelihood of successfully passing the test.

The Cat and Mouse Game
The ongoing battle between developers of ReCAPTCHA and those attempting to bypass it resembles a classic cat and mouse game. As ReCAPTCHA evolves and becomes more sophisticated, bots adapt in kind, seeking new methods to circumvent the system. This constant innovation on both sides ensures that the security of the internet remains a dynamic and evolving challenge.
The Importance of ReCAPTCHA
ReCAPTCHA plays a vital role in safeguarding the internet from a range of malicious activities. Without effective CAPTCHA technology, websites would be vulnerable to spam, fraudulent account creation, web scraping, and other forms of automated abuse. The continued development and improvement of ReCAPTCHA are essential for maintaining a secure and trustworthy online environment.
Bottom Line
ReCAPTCHA, with its multifaceted challenges and cutting-edge technological innovations, serves as an imposing fortress, effectively thwarting the relentless endeavors of robots and automated scripts attempting to impersonate human users. The effectiveness of ReCAPTCHA in the realm of distinguishing between genuine human interaction and automated bot activity is palpably manifest in the remarkably low success rates achieved by the latter. Despite the unwavering tenacity of bots in their ceaseless quest to adapt and devise ingenious strategies, the digital landscape finds itself entrenched in an ever-evolving cat-and-mouse game between the brilliant minds of developers and the relentless determination of malicious actors. This perpetual battle, characterized by constant innovation and adaptation, underscores the dynamic nature of internet security.
The future of ReCAPTCHA appears poised to ascend to even greater heights of sophistication. It is conceivable that the system will integrate novel and intricately layered techniques, rendering the task of bypassing it an increasingly formidable undertaking for bots. The significance of ReCAPTCHA, as the vanguard defender of a secure and trustworthy internet, cannot be overstated. Its continued development stands as a pivotal linchpin in the ongoing crusade against the ever-evolving landscape of online threats that loom menacingly on the digital horizon. The preservation of a safe and dependable online ecosystem hinges upon the continued innovation and enhancement of this formidable guardian of internet security.